

In the list of best streaming apps, HBO Max stands in the top list. HBO Max is a subscription-based streaming service that offers 10,000 hours of original series, blockbuster movies, and TV shows. You can download your favourite video content in HBO Max and can watch it later at any time or anywhere offline. In HBO max, you need to pay $14.99 per month to access the full content. Even you get 7 days free trial for first-time users. HBO max supports most streaming devices like Firestick, Android TV, Apple TV, Roku, and Chromecast. Here, we have listed the ways to cast the HBO Max on TV.
How to Chromecast HBO Max
You can cast HBO Max to your Chromecast-connected TV using the smartphone (Android/iOS) and PC (Windows or Mac). We have given the instructions which you can follow them.
Chromecast HBO Max Using Smartphone
Before getting into the steps, you first need to plug the Chromecast device into the TV and then turn it on.
[1] Connect both devices to the same WiFi connection.
[2] Launch the HBO Max app and choose any video that you want to cast on your TV.
[3] Press the Cast icon on the right top of the screen.
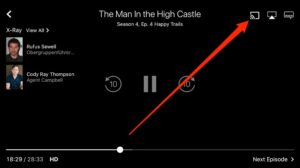
[4] Select Chromecast from the list of available devices.
[5] You can see the video from HBO Max playing on the Chromecast connected TV.
Chromecast HBO Max Using PC Web Browser
[1] Launch the Chrome browser on your PC and visit the HBO max website.
[2] You will see the HBO max home page. On the right top corner, press the three-dotted menu icon.
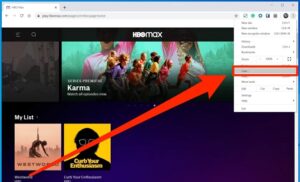
[3] In the list, press on the Cast option.
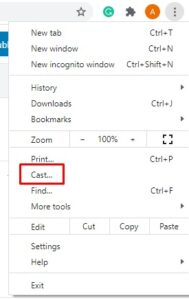
[4] The screen will show you the list of nearby devices. Select your Chromecast.
[5] Press the Source option and choose the Cast tab from the drop-down.
[6] Now, the HBO Max will cast on your TV screen. Choose the video from the app, and it will get play.
That’s it all about casting the HBO max app. HBO Max is one of the best streaming apps that gives you unlimited content and keeps you entertained all the time. Watch your favourite shows or movies with your friends and family on the TV screen.



